
Tầm quan trọng của Robots.txt là tối ưu hóa hiệu quả thu thập dữ liệu cho website. Bài viết này sẽ cung cấp cho bạn kiến thức toàn diện về Robots.txt, giúp bạn tạo và quản lý file này một cách hiệu quả nhất.
1. File Robots.txt là gì?
Robots.txt là một tệp gồm các đoạn mã khai báo cho trình thu thập dữ liệu của các công cụ tìm kiếm (Google, Bing, Cốc Cốc) được truy cập vào những URL nào của website để thu thập dữ liệu.

Lưu ý: File robots.txt hướng dẫn và quy định cho các trình thu thập dữ liệu của công cụ tìm kiếm biết rằng những URL nào được phép truy cập, URL nào thì không. Đây không phải là cách để ẩn một trang/ bài viết nào đó trên website của bạn khỏi công cụ tìm kiếm. Để ẩn một trang/ bài viết bất kỳ khỏi công cụ tìm kiếm một cách hoàn toàn, bạn hãy chặn việc lập chỉ mục cho trang/ bài viết đó bằng tùy chọn noindex.
- Khóa học SEO tại IMTA - Phương pháp SEO quy trình bài bản
- Khóa học quảng cáo Google Ads - Cơ bản đến chuyên sâu
- Khóa Học Digital Marketing - Chạy quảng cáo đa kênh kết hợp
2. Tầm quan trọng của file robots.txt đối với website
File robots.txt quyết định về việc thu thập hoặc không thu thập dữ liệu của các thành phần có trên trên website của bạn. Nhờ đó, kiểm soát và tối ưu việc thu thập dữ liệu, giúp website của bạn không bị đánh giá xấu trước các công cụ tìm kiếm. Đồng thời, giữ nội dung/ thành phần trên website của bạn riêng tư ở một mức độ nào đó.
- Trước khi thu thập dữ liệu website, trình thu thập dữ liệu sẽ tải xuống và phân tích nội dung bên trong file robots.txt của website đó. Từ đấy, lấy cơ sở để xác định những thành phần nào trên website được phép thu thập dữ liệu, thành phần nào không được.
- Việc cấu hình robots.txt giúp bạn ngăn chặn việc truy xuất dữ liệu ở những thành phần không quan trọng trên website. Điều này giúp giảm tải đáng kể việc gửi quá nhiều yêu cầu vào website của bạn từ các trình thu thập dữ liệu như Googlebot chẳng hạn. Nhờ đó giảm được một phần gánh nặng cho máy chủ.
- Kiểm soát những nội dung/ thành phần mà bạn không muốn các công cụ tìm kiếm thu thập dữ liệu và index chúng. Hiểu một cách nôn na là “đẹp khoe, xấu che” – tức là những gì trên website mà bạn thấy không tự tin, không đủ tốt, thì không cho cho công cụ tìm kiếm thu thập dữ liệu ở đó.
- Đối thủ cạnh tranh hoặc kẻ xấu có thể lợi dụng các truy vấn tìm kiếm nội bộ trên website của bạn để thực hiện phá hoại. Trong trường hợp bạn không chặn thu thập dữ liệu ở trang kết quả tìm kiếm nội bộ sẽ là cơ hội tốt để kẻ xấu thực hiện hàng nghìn các truy vấn tìm kiếm “BẨN” khiến website của bạn bị đánh giá thấp. Thông thường kẻ xấu sẽ sử dụng các công cụ tự động để thực hiện các truy vấn BẨN như: từ khóa 18+, lừa đảo,…
Có thể file robots.txt làm được nhiều hơn so với những gì mình đã liệt kê ở trên. Tuy nhiên, trong khuôn khổ bài viết này mình nhấn mạnh vào những lợi ích quan trọng khi sử dụng file robots.txt (tùy chỉnh) cho website, để sát với nhu cầu phổ biến của đại bộ phận người dùng không chuyên.
3. Cấu trúc cơ bản của file robots.txt
Một trong những công tác quan trọng của webmaster là thực hiện cấu hình file robots.txt tùy chỉnh. Tuy nhiên, khi thực hiện việc này nhiều bạn sẽ chọn phương án dùng file robots.txt giống của website khác.
Điều này cũng không không hẳn là sai, nhưng nếu có thể, hãy tìm hiểu thêm về việc cấu hình file robots.txt tùy chỉnh. Như vậy sẽ tối ưu tốt hơn cho website của bạn. Dưới đây, mình sẽ tổng hợp một số kiến thức liên quan đến việc cấu hình file robots.txt tùy chỉnh để bạn tham khảo.
File robots.txt của một số website có nội dung bên trong khá dài và hơi rối để bạn tham khảo. Do đó, để dễ hình dung thì bạn xem qua cấu trúc cơ bản của file robots.txt như sau:
User-agent:
Disallow:
Allow:
Sitemap:
Để hiểu và vận dụng tốt khi cấu hình file robots.txt tùy chỉnh, dưới đây mình sẽ chú thích từng mục có trong cấu trúc cơ bản ở trên để bạn nắm.
Dòng user-agent
Xác định trình thu thập dữ liệu áp dụng những quy tắc bên dưới. Giá trị của user-agent không phân biệt chữ hoa, chữ thường. Bạn muốn cho phép trình thu thập dữ liệu nào thì để tên tương ứng vào, ví dụ: User-agent: Googlebot. Tuy nhiên, hầu hết chúng ta sẽ để khả dụng cho tất cả các trình thu thập dữ liệu hiện có bằng cú pháp User-agent: *
Lệnh disallow
Chỉ định các đường dẫn/ tài nguyên trên website không được phép thu thập dữ liệu và lập chỉ mục (index). Để ngăn chặn thu thập dữ liệu và index với các thư mục/ đường dẫn/ tài nguyên cụ thể, bạn nhập giá trị tương ứng là được. Ví dụ dưới đây là mình ngăn thu thập dữ liệu và index với thư mục wp-admin và wp-includes trên website WordPress.
Disallow: /wp-admin/
Disallow: /wp-includes/
Lưu ý: Giá trị của lệnh disallow có phân biệt chữ hoa chữ thường. Ngoài ra, Google không lập chỉ mục (index) trên các trang không cho phép thu thập dữ liệu (disallow), nhưng vẫn có thể index và hiển thị URL đó trong các kết quả tìm kiếm. URL đó sẽ hiển thị trên kết quả tìm kiếm và không hiển thị đoạn trích. Nếu muốn chặn index cho một trang/ bài viết/ chuyên mục,. . . .thì bạn phải chọn chế độ noindex riêng cho chúng.
Lệnh allow
Lệnh allow chỉ định các đường dẫn/ tài nguyên/ thư mục được phép thu thập dữ liệu và lập chỉ mục. Thoạt nhìn thì có vẻ hơi dư thừa, vì nếu cho phép thu thập dữ liệu thì không cần khai báo allow chi cho rắc rối. Nhưng lệnh allow này có thể áp dụng trong trường hợp đặc biệt như sau:
Ví dụ: Trong thư mục mẹ có 2 thư mục con, nếu chặn thu thập dữ liệu ở thư mục mẹ thì tất cả thư mục/ tập tin bên trong sẽ không được thu thập dữ liệu. Trong khi bạn muốn thu thập dữ liệu của một thư mục con hoặc một tập tin nào đó bên trong thư mục mẹ thì sẽ cần áp dụng lệnh allow.
Disallow: /thu-muc-me/
Allow: /thu-muc-me/ten-tap-tin.php/
Lưu ý: Tương tự như lệnh disallow, giá trị của lệnh allow cũng phân biệt chữ hoa chữ thường, bạn chú ý để đặt giá trị cho chuẩn nhé !
Trường sitemap
Sơ đồ trang web (sitemaps) là danh sách các bài viết, trang hoặc những tập tin có trên Website. Chúng được sắp xếp theo thứ tự theo sơ đồ phân tầng theo từng danh mục, theo thời gian đăng bài hoặc thời gian chỉnh sửa bài viết. Nếu bạn chưa tìm hiểu qua về sitemap thì tham khảo bài viết Sitemap là gì nhé !
Trường sitemap, hãy đặt vào đó URL đầy đủ cho sơ đồ trang web của bạn. Giá trị của trường sitemap là có phân biệt chữ hoa – chữ thường. Bạn có thể chỉ định nhiều trường sitemap và các sitemap không bắt buộc phải cùng nằm chung trên máy chủ của website chính.
Ví dụ:
- sitemap: https://imta.edu.vn/sitemap.xml
- sitemap: https://cdn.imta.edu.vn/sitemap.xml
- sitemap: https://en.imta.edu.vn/sitemap.xml
4. Cấu hình file robots.txt chuẩn SEO cho website WordPress
Nếu như bạn đang bắt đầu học seo website thì việc đầu tiên là bạn phải hiểu được file robots.txt. Nhằm đáp ứng nhu cầu cấu hình file robots.txt chuẩn SEO cho website WordPress, dưới đây mình chia sẻ đến bạn mẫu file robots.txt tiêu chuẩn để bạn tham khảo và áp dụng cho website của bạn. Đồng thời mình cũng chú thích nội dung bên trong để bạn biết được tác dụng của chúng là gì.
Dưới đây là mẫu file Robots.txt chuẩn SEO:
User-agent: *
Allow: /
Disallow: /wp-admin/
Disallow: /wp-content/plugins/
Disallow: /wp-content/themes/
Sitemap: https://example.com/sitemap.xml
User-agent: Bingbot
Disallow: /wp-content/uploads/
User-agent: BaiduBot
Disallow: /wp-content/uploads/images/
Giải thích từng dòng:
User-agent : *: Áp dụng các quy tắc cho tất cả các loại robots.Allow:/: Cho phép robots truy cập vào tất cả các thư mục và trang web trên website.Disallow: /wp-admin/: Chặn robots truy cập vào thư mục quản trị WordPress.Disallow: /wp-content/plugins/: Chặn robots truy cập vào thư mục plugin WordPress.Disallow: /wp-content/themes/: Chặn robots truy cập vào thư mục theme WordPress.Sitemap: https://example.com/sitemap.xml: Cung cấp thông tin về sitemap của website.User-agent: Bingbot: Áp dụng các quy tắc riêng cho Bingbot.Disallow: /wp-content/uploads/: Chặn Bingbot truy cập vào thư mục upload.User-agent: BaiduBot: Áp dụng các quy tắc riêng cho BaiduBot.Disallow: /wp-content/uploads/images/: Chặn BaiduBot truy cập vào thư mục hình ảnh upload.
MẸO: Bạn cũng có thể tham khảo mẫu robots.txt của một website bất kỳ bằng cách thêm đoạn /robots.txt vào website mà bạn muốn kiếm tra, tương tự như dưới đây: https://imta.edu.vn/robots.txt
Hiện tại hầu hết các dịch vụ thiết kế website và website làm từ WordPress đều có chứa file robots.txt, khi nhiều người quan tâm đến SEO hơn thì việc này cũng được làm chuẩn hơn nhiều.
5. Hướng dẫn tạo và gửi file robots.txt
Trên WordPress có khá nhiều hướng dẫn tạo file robot.txt tương ứng với các plugin hỗ trợ như Yoast SEO, Rank Math, All in One SEO,… Tuy nhiên, để đơn giản hóa mình sẽ hướng dẫn bạn triển khai tệp robots.txt theo hướng dẫn tiêu chuẩn của Google.
Lưu ý: Trước khi thực hiện tạo và gửi file robots.txt thì bạn phải kết nối website với Google Search Console. Và hướng dẫn này không chỉ giúp bạn tạo file robots.txt cho website mới mà còn có thể giúp bạn chỉnh sửa, cập nhật lại nội dung file robots.txt đã có.
Bước 01: Bạn nhấn vào công cụ kiểm tra robots.txt của Google. Lúc này công cụ kiểm tra file robots.txt sẽ hiển thị nội dung có trong file robots.txt của website bạn. Tuy nhiên, đây chỉ là nội dung file robots.txt mặc định của một website WordPress bất kỳ sau khi cài.
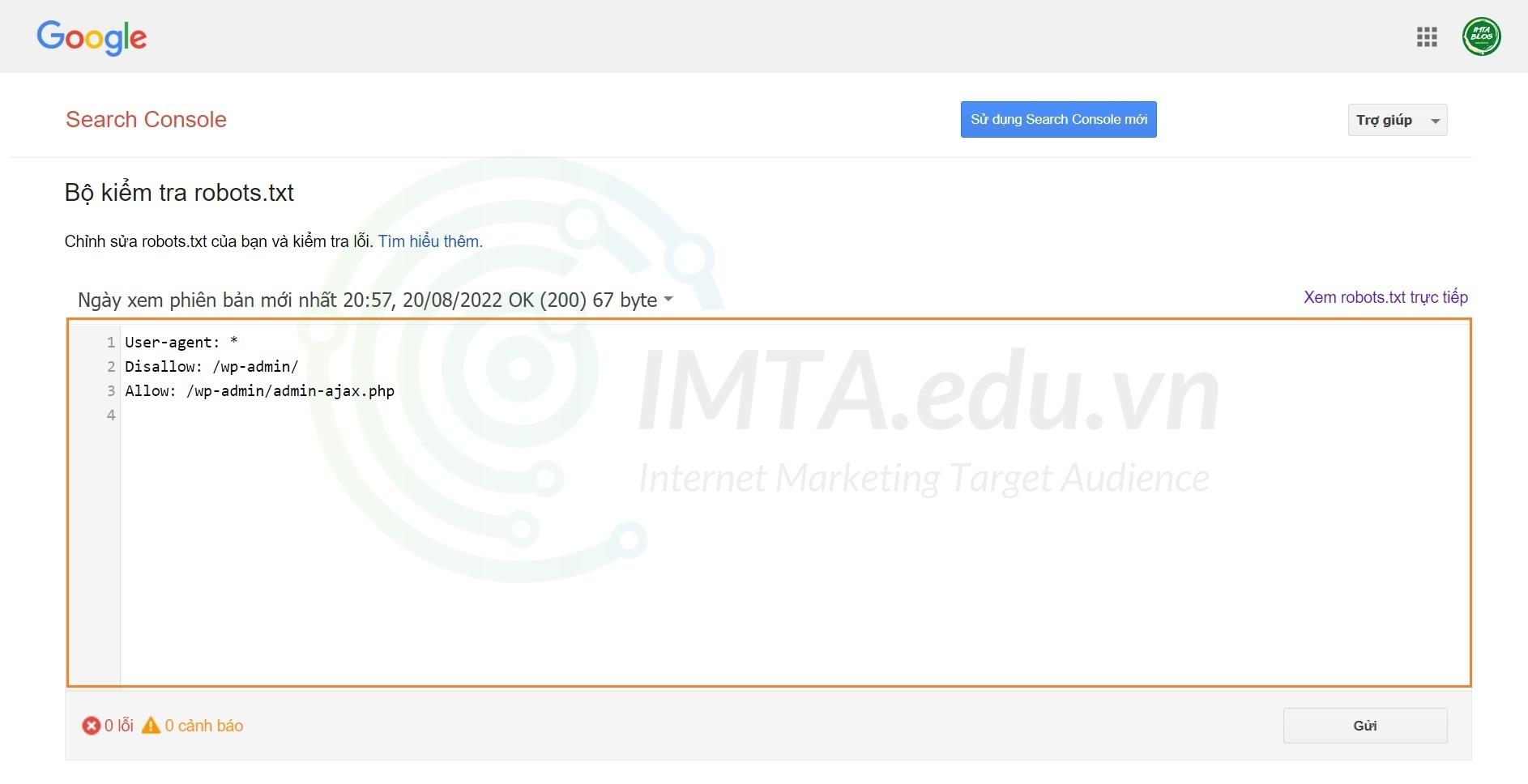
Bước 02: Copy nội dung file robots.txt mà bạn đã tùy chỉnh sẵn, hoặc lấy nội dung file robots.txt tiêu chuẩn cho website WordPress mà mình đã chia sẻ ở trên cũng được. Sau đó dán đè lên nội dung robots.txt mặc định. Sau đó nhấn vào nút Gửi như mình khoanh đỏ ở hình bên dưới. Tiếp đến là chọn mục Tải xuống.
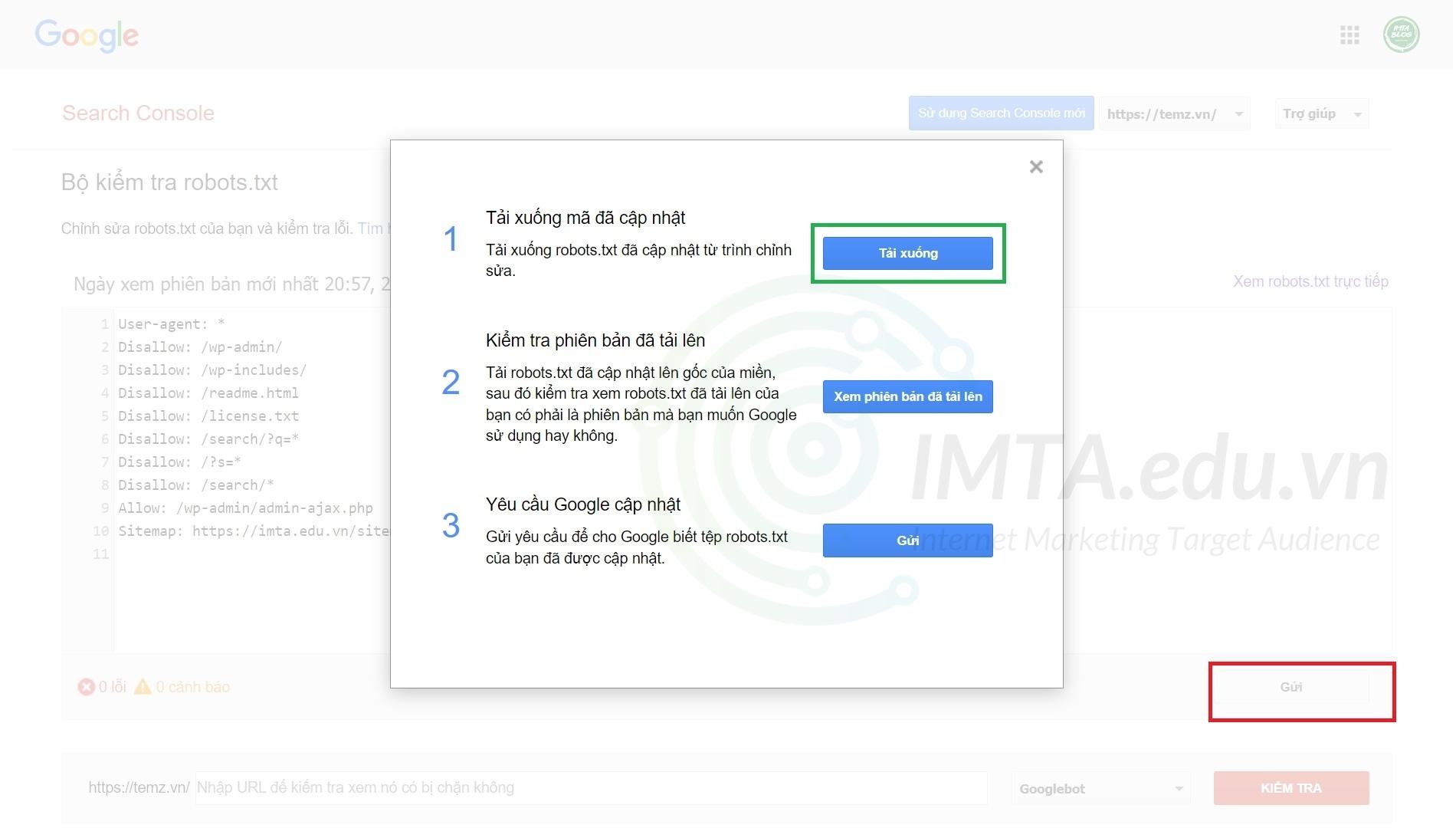
Bước 03: Uplad file robots.txt vừa tải về ở trên lên thư mục gốc (Root) của website. Để cho dễ hình dung, bạn upload vào bên trong thư mục chứa toàn bộ mã nguồn website WordPress của bạn giống như hình bên dưới:
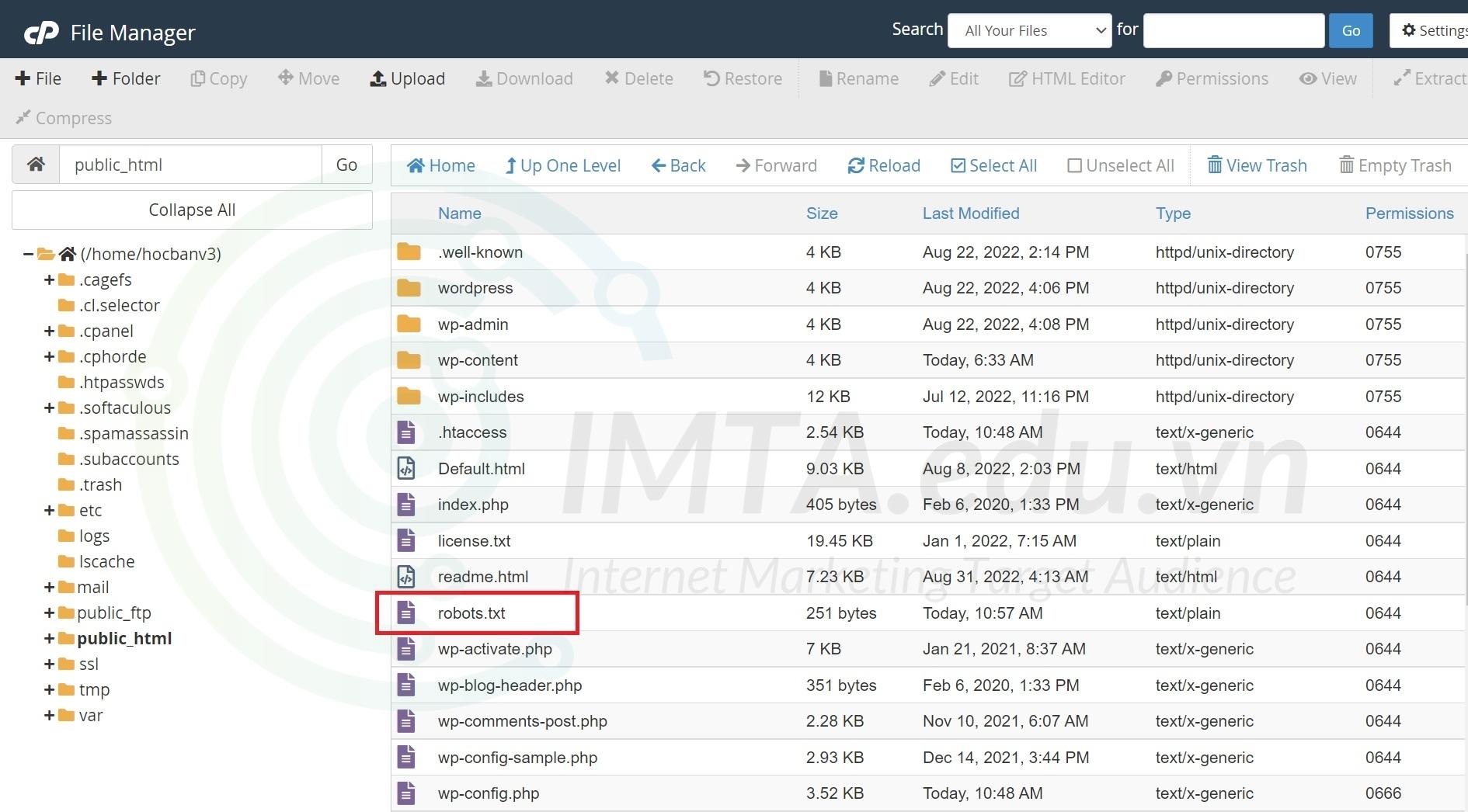
Lưu ý: Nếu bạn dùng hosting cPanel thì thường sẽ nằm trong thư mục public_html. Tuy nhiên, trong một số trường hợp dùng addon domain, ví dụ: ngoài website chính có tên miền là domain.com trên host đó còn chạy các web khác như: domain1.com, domain2.com.. thì file robots.txt cần cài cho website nào sẽ nằm trong thư mục của website đó, không nằm trong thư mục public_html của website chính. Ở trường hợp này thì bạn cứ upload lên thư mục cùng cấp với các thư mục wp-content, wp-includes như hình trên là được.
Bước 04: Lúc này bạn có thể nhấn vào nút Xem phiên bản đã tải lên để kiểm tra xem nội dung trong file robots.txt vừa upload có giống như bản bạn đã cấu hình không nhé, nếu không giống thì có thể bạn đã upload nhầm thư mục rồi. Nếu nội dung giống như file robots.txt đã cấu hình thì bạn nhấn vào nút Gửi như mình khoanh ở hình bên dưới. Chờ trong vài giây sẽ có thông báo thành công. Lúc này bạn ra bên ngoài, tải lại trang hoặc chạy lại công cụ kiểm tra file robots.txt ở bước 01 thì sẽ thấy nội dung bên trong đã thay đổi như đã chỉnh sửa.
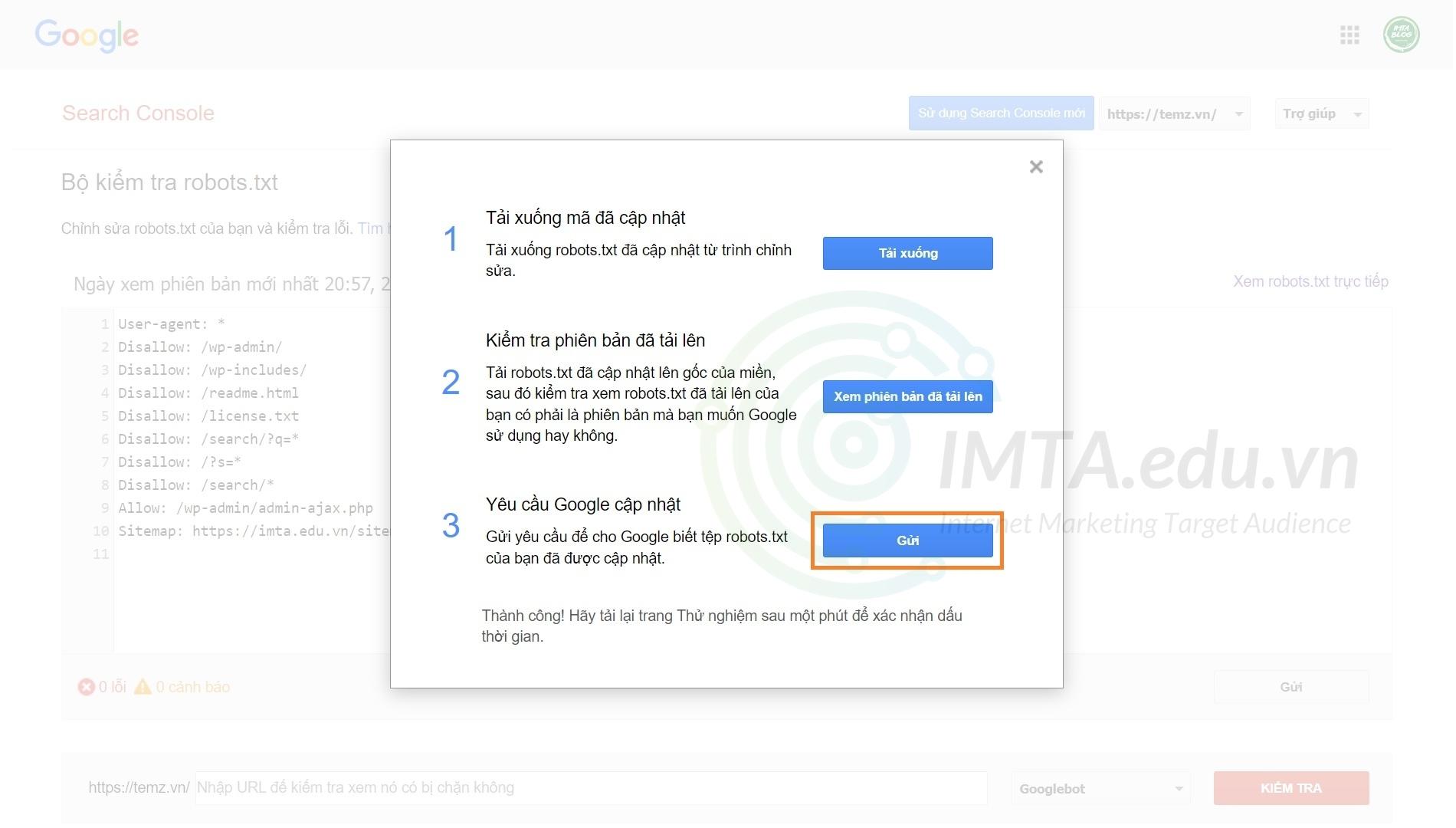
Như vậy là quá trình tạo và gửi file robots.txt cho website đã hoàn tất. Cách làm này không chỉ áp dụng riêng cho website dùng WordPress mà các mã nguồn khác cũng áp dụng tương tự.
6. Một số câu hỏi thường gặp
Trên đây là tổng quan kiến thức về Robots.txt và cách tạo file xác nhận chuẩn mà IMTA đã chia sẻ. Hy vọng với những thông tin chia sẽ trên sẻ giúp bạn hiểu rõ và tạo được file Robots.txt phù hợp với website của mình.
Để cập nhật thêm thông tin về Robots.txt được công bố chính thức của Google, truy cập tại: https://developers.google.com/search/docs/crawling-indexing/robots/